

- Like
- SHARE
- Digg
- Del
- Tumblr
- VKontakte
- Flattr
- Buffer
- Love This
- Save
- Odnoklassniki
- Meneame
- Blogger
- Amazon
- Yahoo Mail
- Gmail
- AOL
- Newsvine
- HackerNews
- Evernote
- MySpace
- Mail.ru
- Viadeo
- Line
- Comments
- Yummly
- SMS
- Viber
- Telegram
- JOIN
- Skype
- Facebook Messenger
- Kakao
- LiveJournal
- Yammer
- Edgar
- Fintel
- Mix
- Instapaper
- Copy Link
With the annual ISC High Performance supercomputing conference kicking off this week, Intel is one of several vendors making announcements timed with the show. As the crown jewels of the company’s HPC product portfolio have launched in the last several months, the company doesn’t have any major new silicon announcements to make alongside this year’s show – and unfortunately Aurora isn’t yet up and running to take a shot at the Top 500 list. So, following a tumultuous year thus far that has seen significant shifts in Intel’s GPU roadmap in particular, the company is using ISC to recompose itself and use the backdrop of the show to lay out a fresh roadmap for HPC customers.
Most notably, Intel is using this opportunity to better explain some of the hardware development decisions the company has made this year. That includes Intel’s pivot on Falcon Shores, transforming it from XPU into a pure GPU design, as well to a few more high-level details of what will eventually become Intel’s next HPC-class GPU. Although Intel would clearly be perfectly happy to keep selling CPUs, the company has (and continues to) realign for a diversified market where their high-performance customers need more than just CPUs.

CPU Roadmap: Emerald Rapids and Granite Rapids Xeons in the Works
As noted earlier, Intel isn’t announcing any new silicon today across any part of their HPC portfolio. So Intel’s latest HPC roadmap is essentially a condensed version of their latest data center roadmap, which was first laid out to investors towards the end of March. HPC is, after all, a subset of the data center market, so the HPC roadmap reflects this.
I won’t go into Intel’s CPU roadmap too much here, since we just covered it a couple of months ago, but the company is once again reiterating the rapid-fire run they intend to make through their Xeon products over the next 18 months. Sapphire Rapids is only a few months into shipping, but Intel intends to have its same-platform successor, Emerald Rapids, ready for delivery in Q4. Meanwhile Granite Rapids, Intel’s first P-Core Xeon on the Intel 3 process, will launch with its new platform in 2024. Granite will also be Intel’s first product to support higher bandwidth MCR DIMM memory, which was similarly demonstrated back in March.

Notably here, despite the HPC audience of ISC, Intel still hasn’t announced a successor to the current-generation HBM-equipped Sapphire Rapids Xeon with HBM – which the company brands as the Xeon Max Series. Intel’s rather proud of the part – pointing out that it’s the only x86 processor with HBM whenever they get the chance – and it’s a core part of the Aurora supercomputer. We had been expecting its successor to fall into place with Falcon Shores back when it was an XPU, but since Falcon pivoted to being a GPU, there’s been no further sign of where another HBM Xeon will land on Intel’s roadmap.
In the meantime, Intel is eager to demonstrate to the ISC audience the performance benefits of having so much high bandwidth memory on-package with the CPU cores – and especially before AMD launches their EPYC Genoa-X processors with their supersized, 1GB+ L3 caches. To that end Intel has published several fresh benchmarks comparing Xeon Max Series processors to EPYC 7000 and 9000 series chips, which as they’re vendor benchmarks I won’t get into here, but you can find in the gallery below.






GPU Roadmap Today: Ponte Vecchio Now Shipping, Additional SKUs To Launch in Coming Months
The GPU counterpart to Sapphire Rapids with HBM for the HPC crowd is Intel’s Data Center GPU Max series, otherwise known as Ponte Vecchio. The massively tiled chip is still unlike any other GPU on the market, and Intel’s IFS foundry arm is quite proud to point out to potential customers that they’re able to reliably assemble one of the most advanced chips on the market, with nearly four dozen chiplets to perfectly place to bring the whole thing together.
Ponte Vecchio has had a long and exhausting development cycle for Intel and its customers alike, so they’re taking a bit of a victory lap at ISC to celebrate that accomplishment. Of course, Ponte Vecchio is just the beginning of Intel’s HPC GPU efforts, and not the end. So they are still in the process of building up the OneAPI software and tool ecosystem to support the hardware – all while being mindful of the fact that they need a strong software ecosystem to match rival NVIDIA, and to capitalize on AMD’s current shortcomings.
Despite being nearly a generation late, Intel surprisingly has some benchmarks comparing Ponte Vecchio to NVIDIA’s new Hopper architecture-based H100 accelerators. With that said, these are for Intel’s top-end OAM-based modules against H100 PCIe cards; so cherry picking aside, it remains to be seen just how well things would look with a more apples-to-apples hardware comparison.







Speaking of OAM modules, Intel is using the show to announce a new 8-way Universal Baseboard (UBB) for Ponte Vecchio. Joining Intel’s existing 4-way UBB, the x8 UBB will allow for 8 Data Center Max GPU modules to be placed on a single server board, similar to what NVIDIA does with their HGX carrier boards. If Intel is to go toe-to-toe with NVIDIA and to capture part of the HPC GPU market, then this is one more area where they’re going to need to match NVIDIA’s hardware offerings. Thus far Supermicro and Inspur are signed up to distribute servers using the new x8 UBB, and if things go their way, these shouldn’t be Intel’s only customers.

Along with the UBB announcement, Intel is also providing for the first time a detailed, month-by-month roadmap for Data Center Max GPU product availability. Now that Intel has nearly satisfied their Aurora order, the first parts have been vaguely available to select customers, but now we get to see where things stand in a bit more detail. Per that roadmap, OEMs should be ready to begin shipping 4-way GPU systems in June, while 8-way systems will be a month behind that in July. Meanwhile OEM systems using the PCIe version of Ponte Vecchio, the Data Center GPU Max 1100, will be available in July. Finally, a detuned version of Ponte Vecchio for “different markets” (read: China) will be available in Q4 of this year. Details on this part are still slim, but it will have reduced I/O bandwidth to meet US export requirements.
GPU Roadmap Tomorrow: All Roads Lead to Falcon Shores
Looking past the current iteration of the Data Center GPU Max series and Ponte Vecchio, the next GPU in the pipeline for Intel’s HPC customers is Falcon Shores. As we detailed back in March, Falcon Shores will be taking on a significantly different role in life than Intel first intended, following the cancellation of Rialto Bridge, Ponte Vecchio’s direct descendent. Instead of being Intel’s first combined CPU + GPU product – a flexible XPU that can use a mix of CPU and GPU tiles – Falcon is now going to be a purely GPU product. Unfortunately, it’s also picking up a year’s delay in the process, pushing it to 2025, meaning that Intel’s HPC GPU lineup is purely Ponte based for the next couple of years.
The cancellation of Rialto Bridge and the de-XPUing of Falcon Shores created a good deal of consternation within the media and HPC community, so Intel is using this moment to get their messaging in order, both in terms of why they pivoted on Falcon Shores, and just what it will entail.
The long and short of the story there is that Intel has decided that they mistimed the market for their first XPU, and that Falcon Shores as an XPU would have wound up being premature. In Intel’s collective mind, because these products offer a fixed ratio of CPU cores to GPU cores (vis a vie the number of tiles used), they are best suited for workloads that closely match those hardware allocations.
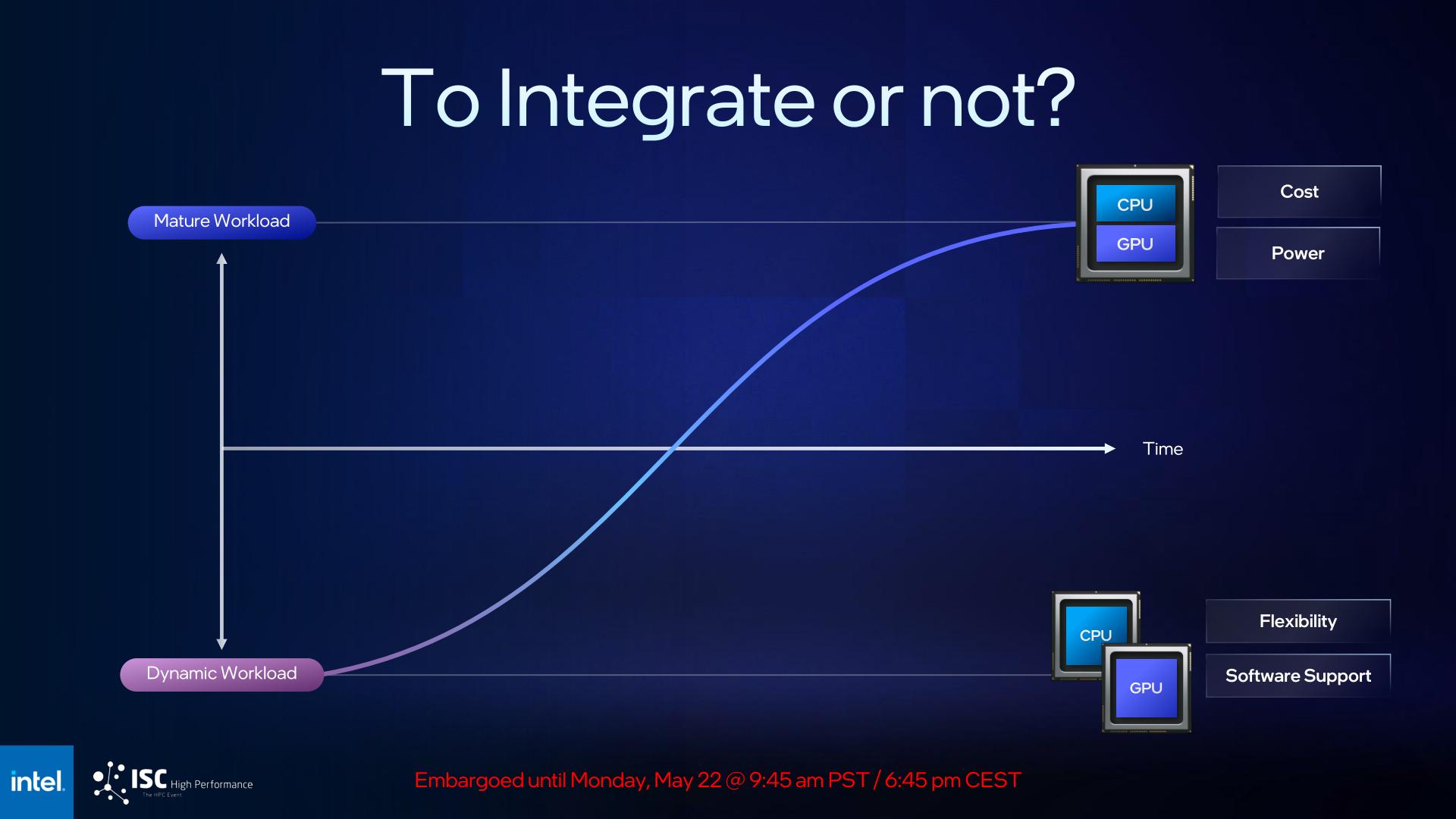
And what workloads are those? Well, that ends up being the 100B transistor question. Intel was expecting the market to be more settled than it actually has been – that is to say, it’s been more dynamic than Intel was expecting – which Intel believes makes an XPU with its fixed ratios harder to match to workloads, and harder to sell to customers. As a result, Intel has backed off on their integration plans, leading to the all-GPU Falcon Shores.

Now with that said, Intel is making it clear that they’re not aborting the idea of an XPU entirely; only that Falcon Shores in 2024/2025 is not the right time for it. So, Intel is also confirming that they will be developing a tile-based XPU as a future, post-Falcon Shores product (possibly as Falcon Shores’ successor?). There are no further details on that future XPU than this, but for now, Intel still wants to get to CPU/GPU integration once they deem the workloads and the market are ready. This also means that Intel is effectively ceding the mixed CPU-GPU accelerator market to AMD (and to a lesser extent, NVIDIA) for at least a few more years, so make of that what you will with Intel’s official rationale for delaying their own XPU.

As for the all-GPU Falcon Shores, Intel is sharing just a hair more about the design and capabilities of their next-generation PC GPU. As you’d expect from a design that started as a tiled product, Falcon remains a chiplet-based design. Though it’s unclear just what kinds of chiplets Intel will use (if they’ll be homogenous GPU blocks or not), they will be paired with HBM3 memory, and what Intel terms as “I/O designed to scale.” In light of Intel’s decision to delay XPUs, this will be how they deliver a flexible CPU-to-GPU ratio for their HPC customers via the tried and true way: add as many GPUs to your system as you need.
Falcon Shores will also support Ethernet switching as a standard feature, which will be a major component in supporting the kind of very large meshes that customers are building with their supercomputers today. And since these parts will be discrete GPUs, Intel will be embracing CXL to deliver additional functionality to system designers and programmers. Given the timing, CXL 3.0 functionality is a safe bet, with things like P2P DMA and advanced fabric support going hand-in-hand with what the HPC market has been building towards.
And with a few years of experience behind them at that point, Intel expects to be able to leverage OneAPI even harder. Especially as they’ll need the help of software to abstract the CPU-GPU I/O gap that Falcon Shores the XPU was otherwise going to be able to close in hardware.




Aurora Update: 10K+ Blades Delivered, Additional Specifications Disclosed
Finally, Intel is also offering an update on Aurora, their Sapphire Rapids with HBM + Ponte Vecchio based supercomputer for Argonne National Laboratory. A product of two delayed processors, Aurora is itself a delayed system that Intel has been working to catch up on. In terms of the hardware itself, the light is in sight at the end of the tunnel, as Intel is wrapping up delivery of Aurora’s compute blades.
As of today, Intel has delivered over 10,000 blades for Aurora, very close to the final expected tally for the system of 10,624 nodes. Unfortunately, delivered and installed are not quite the same things here; so while Argonne has much of the hardware in hand, Aurora isn’t ready to make a run at the Top500 supercomputer list, leaving the AMD-based Frontier system to hold the top spot for another 6 months.
On the plus side, with Aurora’s hardware shipments nearly complete, Intel is finally disclosing a more detailed summary of Aurora’s hardware specifications. This includes not only the number of nodes and the CPUs and GPUs within them, but also the various amounts of memory and storage available to the supercomputer.
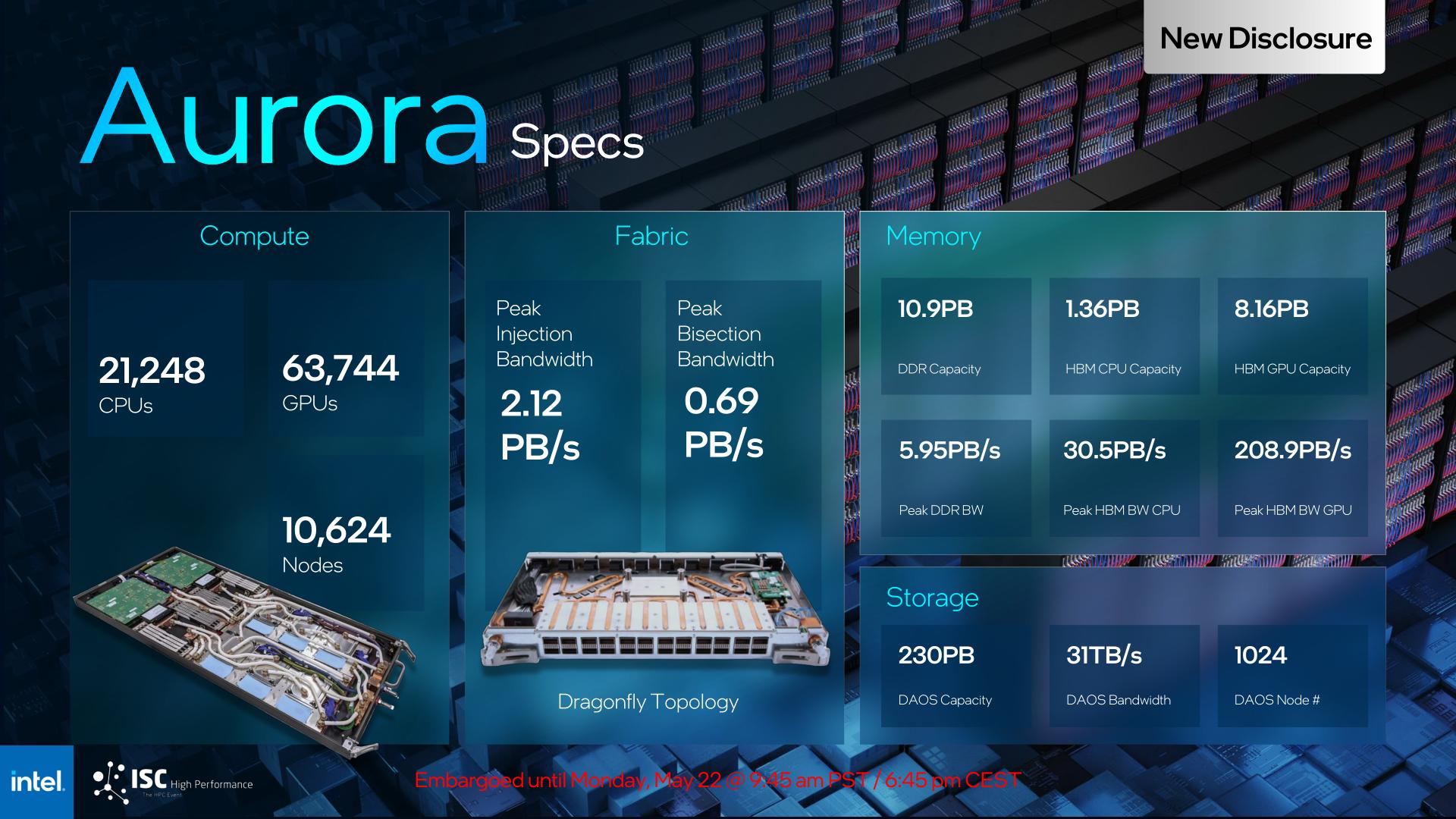
With 2 CPUs and 6 GPUs in each node, the fully assembled Aurora will be comprised of 21,248 Sapphire Rapids CPUs and 63,744 Ponte Vecchio GPUs, and as previously disclosed, the peak performance of the system is expected to be in excess of 2 ExaFLOPS of FP64 compute. Besides the 128GB of HBM on each GPU and 64GB of HBM on each CPU, there’s an additional 1 TB of DDR5 memory installed on each node. Peak bandwidth will come from the HBM for the GPUs, at 208.9PB/second, though even the “slow” DDR5 is still an aggregate 5.95PB/second.

And since no supercomputer announcement would be complete without some mention of AI, Intel and Argonne are developing a generative/large-language-model AI for use on Aurora, which they are calling for now the Generative AI for Science. The model will be developed specifically for scientific use, and Intel expects it to be a 1 trillion parameter model (which would place it between GPT-3 and GPT-4 in size). The expectation is that they’ll use Aurora for both the training and inference of this model, though in the case of the latter, that would presumably be just a fraction of the system given the much lower system requirements for inference.
At this point Aurora remains on schedule for a launch this year. Besides beginning production use, Intel expects that Aurora will be able to place on the Top500 list for its November update, at which point it is expected to become the most powerful supercomputer in the world.













